Last year, Eva Vivalt of the Australian National University wrote a paper analyzing the results of international development programs like microloans, deworming, cash transfers, and so forth. This chart shows the basic results:
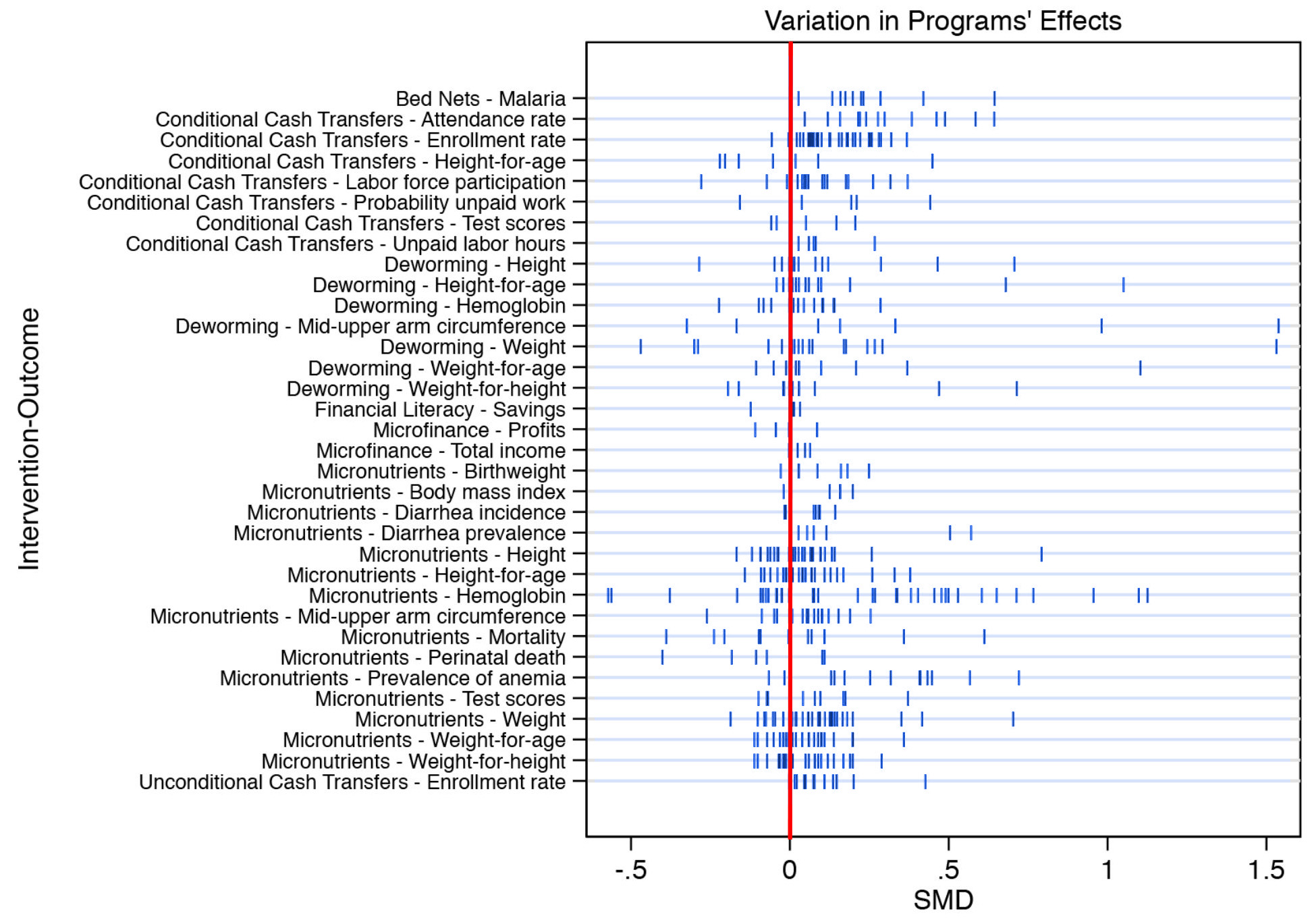
There are two things to notice. First, there’s not a lot of clustering. For nearly all these programs, the results are pretty widely dispersed. Second, where there is clustering, it’s right around zero, where the results are the least meaningful. A few months after Vivalt published her paper, Robert Wiblin described it this way:
The typical study result differs from the average effect found in similar studies so far by almost 100%. That is to say, if all existing studies of an education program find that it improves test scores by 0.5 standard deviations — the next result is as likely to be negative or greater than 1 standard deviation, as it is to be between 0-1 standard deviations….She also observed that results from smaller studies conducted by NGOs — often pilot studies — would often look promising. But when governments tried to implement scaled-up versions of those programs, their performance would drop considerably.
Last week, a charity announced a dramatic specific confirmation of Vivalt’s general results. Kelsey Piper provides the details:
No Lean Season is an innovative program that was created to help poor families in rural Bangladesh during the period between planting and harvesting (typically September to November). During that period, there are no jobs and no income, and families go hungry….No Lean Season aimed to solve that by giving small subsidies to workers so they could migrate to urban areas, where there are job opportunities, for the months before the harvest. In small trials, it worked great.
….Evidence Action wanted more data to assess the program’s effectiveness, so it participated in a rigorous randomized controlled trial (RCT) — the gold standard for effectiveness research for interventions like these — of the program’s benefits at scale. Last week, the results from the study finally came in — and they were disappointing. In a blog post, Evidence Action wrote: “An RCT-at-scale found that the [No Lean Season] program did not have the desired impact on inducing migration, and consequently did not increase income or consumption.” (The emphasis is in the original blog post.)
This admission was a big deal in development circles. Here’s why: It is exceptionally rare for a charity to participate in research, conclude that the research suggests its program as implemented doesn’t work, and publicize those results in a major announcement to donors.
I’m writing about this as much as a warning to myself as a warning to everyone else. In one sense, this is just part of the recent replicability crisis in the social sciences, but it really goes back farther than that. It’s been pretty well known for a very long time that the biggest problem with interventions like these is scalability. Pilot studies have the luxury of being (relatively) easy to fund since they’re small; being able to choose sites where everyone is excited about the program and buys into it; not having to account for long-term feedback caused by the existence of the program itself (i.e., people get accustomed to the program as a baseline rather than as an interesting new thing); and generally having to deal with less diversity in their sample population, which makes a simple one-size-fits-all program easier to implement and less likely to have to deal with community pushback.
Needless to say, this wide dispersion of results from small studies makes it really easy to cherry pick them to demonstrate whatever point you feel like making. I try to be tolerably honest in my reporting, but it’s nearly impossible not to fall prey to this from time to time.
There’s not a lot more to say about this except to make a few brief points:
- Be skeptical of small studies. “This is just a single study” isn’t merely boilerplate. It’s a real warning.
- Be very skeptical of claims that small programs are likely to scale well to state or national size. They might, but you should demand real evidence of this.
- Researchers with the means should be far more willing to follow up pilots with large-scale programs, and far more willing to admit when they don’t work.
This is not a counsel of despair. The truth is that most social interventions at scale just don’t work all that well. This is hard stuff! Still, small pilot studies are the only means we have to provide direction for further research, and large programs that provide even a modest benefit should be considered worthwhile. In other words, we should probably be more demanding of small studies, but less demanding in our expectations for large programs.